从被动验证到主动自证:SmartSnap重新定义GUI智能体的证据哲学
做研究的人都知道,验证永远比执行更难。这句话在LLM/VLM驱动的智能体领域体现得尤为明显。
问题的根源:验证的困境
传统的智能体验证范式遵循一个朴素的逻辑:先让智能体把任务做完,再通过外部系统去复核它的每一步操作。这种方式在实验室环境下勉强能跑通,但一旦面对真实世界的复杂场景,问题就接踵而来。
手工设计的校验机制依赖预先编写的评估脚本,泛化能力几乎为零。每换一个新的应用环境,工程师就得重新写一套验证规则。更要命的是,轨迹级验证需要把整条操作路径扔给裁判模型,环境噪声和信息冗余让评分可靠性大打折扣。此外,时效性环境中的操作往往因为页面刷新而失效,导致验证系统给出错误的失败判定。
SmartSnap的核心洞察
SmartSnap团队没有在验证器端做文章,而是反其道而行之:与其让裁判更聪明,不如让执行者自己学会证明自己。他们提出的Self-VerifyingAgent范式,本质上是将智能体从"被动执行者"升级为"主动自证者"。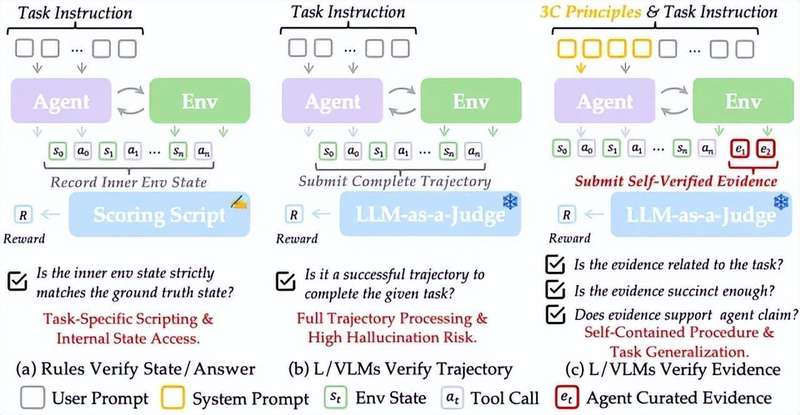
实现方式出奇简洁:智能体在执行任务的同时,主动收集、筛选并提交一份"证据快照集"。这份快照就是任务的"结项报告",验证者只需看一眼,就能确认任务是否成功闭环。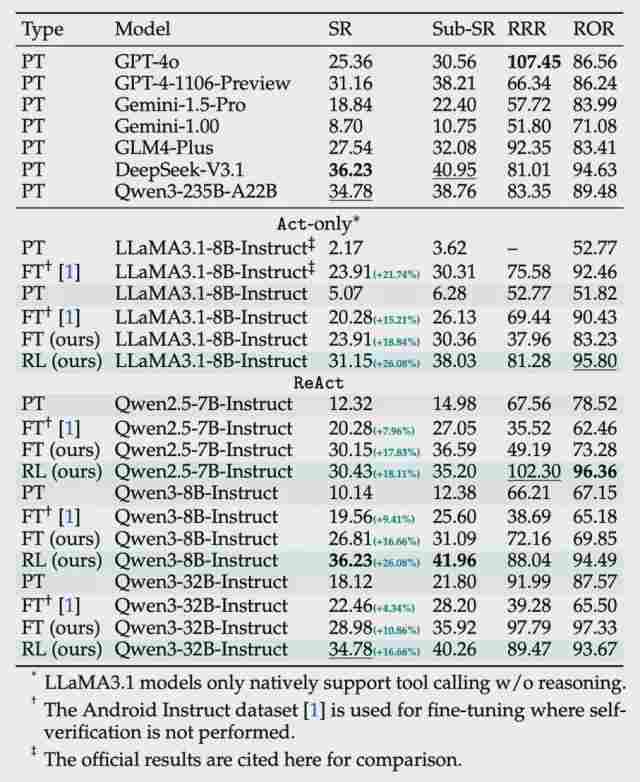
3C原则:证据策展的方法论
SmartSnap为证据收集制定了三条铁律。Completeness(完整性)要求证据必须足以证明任务闭环,不能遗漏关键环节。Conciseness(简洁性)强调不要冗长的视频流,只要最关键的几张定格画面。Creativity(创造性)则允许智能体为了获取证据而执行"额外操作"——比如订完机票后主动跳回订单页截图。
这三条原则的精妙之处在于,它们共同构成了一套轻量级的证据质量标准,既不会给验证者造成信息过载,又能确保任务完成度可被可靠评估。
GRPO+内在奖励:训练机制的革新
在训练层面,团队采用GRPO算法配合精心设计的内在奖励机制。核心目标是引导智能体在保证任务成功率的同时,不断优化证据质量。奖励函数的设计尤其关键——它必须能够区分"完成任务"和"高质量自证"两个维度,同时抑制rewardhacking行为。
实验数据印证了这套机制的有效性。在AndroidLab等复杂任务上,不同规模的模型均实现了显著的性能提升,最高增幅达26.08%。更值得关注的是,经过SmartSnap训练的中等参数模型(如Qwen3-32B),在自证能力的加持下,其表现竟能与DeepSeek-V3等开源大模型持平。
实践价值:降本增效的底层逻辑
从工程角度看,SmartSnap的核心价值在于重构了验证的成本结构。传统方案需要为每个新环境编写校验脚本,需要裁判模型实时监听操作轨迹。SmartSnap让智能体自己边做边收集证据,将验证器的审核压力降至最低。
具体指标更具说服力:平均每个任务只需提交1.5张快照证据。这意味着后端验证系统的工作量被压缩到了极致。团队还观察到,经过训练的智能体在交互轮数上持续减少,证明其正在从"蛮力执行"走向"认知协同"。
当然,这套方案并非万能。在地图APP等需要复杂路径规划的任务上,智能体仍表现出知识欠缺导致的收敛困难。这提示我们,证据能力与领域知识需要协同进化。
范式转移:从蛮干到可信
SmartSnap的出现,本质上标志着GUI智能体领域的一次范式转移。过去的核心问题是"AI能不能完成任务",现在的问题变成了"AI如何证明它完成了任务"。这个转变看似微小,实则深远——它让AI系统从"能干"走向"可信",为大规模、低成本的AI部署铺平了道路。
论文链接:https://arxiv.org/abs/2512.22322
代码链接:https://github.com/TencentYoutuResearch/SmartSnap